はじめに:なぜ今、AIを理解する必要があるのか
ChatGPTが登場してから、わずか5日で100万ユーザー、2ヶ月で1億ユーザーを突破しました。これは人類史上、最も速く普及したサービスです。スマートフォンが1億人に到達するまで約7年かかったことを考えると、その衝撃の大きさが伝わるでしょう。
しかし、AIが急速に普及するにつれて、技術そのものと一般の人々との「知識の壁」も大きくなっています。「AIって結局何なの?」「ChatGPTはどうやって賢くなったの?」「半導体と何の関係があるの?」という疑問を持っている方は非常に多いのではないでしょうか。
本記事では、ITアーキテクトとして20年以上の現場経験を持つ筆者が、AIの基本的な仕組みから最新技術トレンド、そして社会への影響まで、体系的かつ深く解説します。単なる表面的な説明ではなく、現場目線での実践的な視点も加えながら、非エンジニアの方でも理解できるよう丁寧に説明していきます。
第1章:LLM(大規模言語モデル)とは何か
1-1. LLMの定義と規模の爆発的拡大
LLM(Large Language Model)とは、「超巨大な言語モデル」のことです。私たちが日常的に使っているChatGPTやClaude、Geminiといったサービスは、すべてこのLLMを基盤としています。
「モデル」とは、大量のデータから学習して、予測や判断ができるようになったAIシステムのことです。そして「大規模」というのは、文字通りその規模が桁外れに大きいことを指します。
その規模感を数字で表すと:
| モデル | パラメータ数 | 時期 |
|---|---|---|
| GPT-1 | 約1億 | 2018年 |
| GPT-3 | 1,750億 | 2020年 |
| GPT-4 | 推定1兆8,000億 | 2023年 |
「パラメータ」とは、AIが学習を通じて獲得した知識や判断パターンの数です。人間の脳にある神経細胞(ニューロン)の数が約1,400億と言われているので、GPT-3の1,750億パラメータは既に人間の脳のニューロン数を超えているということになります。
1-2. なぜ大きければ大きいほど賢くなるのか?「スケーリング則」
ここで非常に興味深い現象があります。モデルが大きくなればなるほど、性能が劇的に向上するという「スケーリング則(Neural Scaling Law)」です。OpenAIが提唱したこの法則は、AIの世界に革命をもたらしました。
これは生物学における「クライバーの法則」に似ています。動物は体が大きくなるほど、体重あたりのエネルギー効率が良くなります。象はネズミよりも体重あたりの食事量が少なくて済む。AIも同様に、モデルが大きくなるほどパラメータ当たりの学習効率が高まるのです。
さらに驚くべきことが起きます。モデルが一定の規模を超えると、誰も教えていない能力が突然現れるのです。これを「創発(Emergence)」と言います。
例えば:
- 「算数の文章題が急に解けるようになった」
- 「翻訳を学習していないのに、翻訳ができるようになった」
- 「コードを教えていないのに、プログラムが書けるようになった」
研究者たちも「なぜそうなるのか」を完全には解明できていません。これはAIの最も神秘的な側面の一つです。
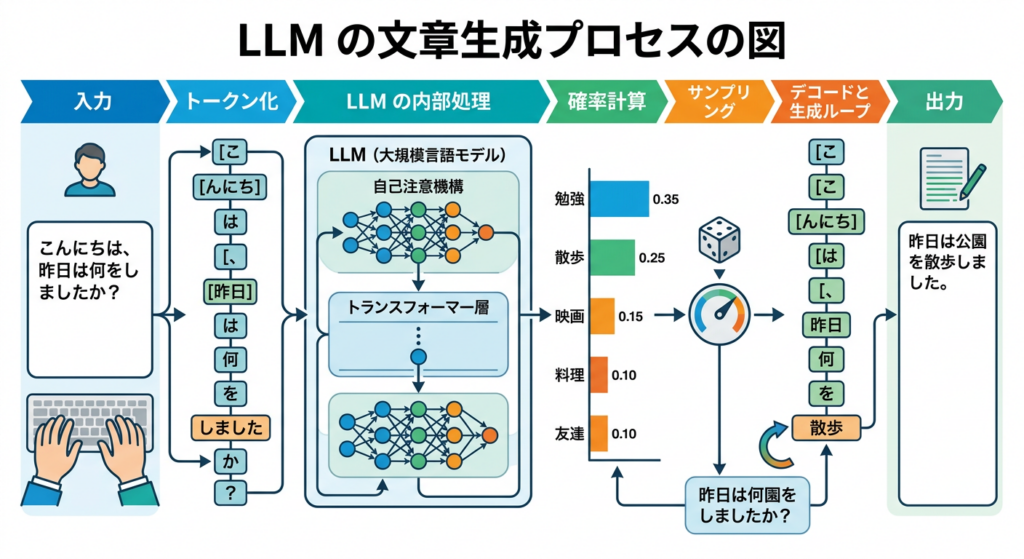
1-3. LLMの基本的な動作原理:「次の単語予測」
ChatGPTがどうやって文章を生成するか、その仕組みは実はとてもシンプルです。**「次に来る単語を予測する」**ことの繰り返しです。
例えば「今日の天気は」という文があったとき、AIは:
- 「いい」:30%
- 「悪い」:25%
- 「晴れ」:20%
- 「雨」:15%
- その他:10%
というように、膨大な学習データからパターンを学習し、確率的に最も自然な次の単語を選んでいます。これを連続して行うことで、流暢な文章が生成されるのです。
一部の研究者は、このようなLLMを「確率的なオウム(Stochastic Parrot)」と批判的に呼ぶこともあります。意味を理解しているのではなく、統計的に「それらしい」言葉を出力しているだけだ、という批判です。
これは的を射た批判でもあり、後述する「ハルシネーション問題」の根本的な原因でもあります。
第2章:AIが言語を理解する仕組み|埋め込みとアテンション
2-1. コンピューターに言語を理解させる「埋め込み(Embedding)」
コンピューターは本来、0と1しか理解できません。では、どうやって「言葉」を処理するのでしょうか?
そこで使われるのが**「埋め込み(Embedding)」**という技術です。単語や文章の特徴を数値(ベクトル)で表現する手法です。
色を「赤=255, 緑=0, 青=0」という3つの数値で表現するのと同じように、単語も多次元のベクトルで表現します。例えば:
- 「王様」→ [0.8, 0.3, 0.9, 0.1, …]
- 「女王」→ [0.8, 0.7, 0.9, 0.1, …]
- 「男性」→ [0.2, 0.3, 0.1, 0.8, …]
この数値表現のおかげで、「王様 – 男性 + 女性 = 女王」という意味的な計算ができるようになります。単語の意味的な近さや遠さが、数値的な距離で表現されるのです。
実際のLLMでは、OpenAIの埋め込みAPIが3,072次元のベクトルを使用しています。私たちが3次元の空間しか直感的に理解できないのに対し、AIは3,000次元以上の超高次元空間で言葉の意味を扱っているのです。
また、文章はまず「トークン」という単位に分割されます。トークンは単語より少し細かい単位で、英語なら1単語≒1〜2トークン、日本語の漢字1文字は1〜2トークン程度です。AIはこのトークン単位で数値に変換し、計算を行っています。
2-2. 文脈を理解する革命的技術「アテンション(Attention)」
言葉を数値化しただけでは不十分です。文章の意味は、単語の順序や文脈によって大きく変わるからです。
例えば「私は銀行に行った」という文があったとき、「銀行」が「金融機関」なのか「川の土手」なのかは、前後の文脈で決まります。
この文脈の把握を可能にするのが「アテンション(Attention)」という技術です。
アテンションは、文章の中で「どの単語が今の判断に重要か」を計算し、重要な単語により多くの注意(アテンション)を向ける仕組みです。英語の勉強で大切な単語に蛍光ペンで線を引くイメージです。
より具体的に言うと、アテンションは「検索(Search)」に例えることができます:
- クエリ(Query):今、注目している単語
- キー(Key):他の単語たちの「タグ」
- バリュー(Value):他の単語の実際の情報
クエリとキーの類似度を計算して、どのバリューをどれだけ参照するかを決める。これがアテンションの本質です。
2-3. 現代AIの根幹「トランスフォーマー(Transformer)」
2017年、Googleの研究者たちが「Attention is All You Need」という論文を発表しました。タイトル通り、「アテンションだけで全てうまくいく」という衝撃的な内容でした。これがトランスフォーマーアーキテクチャです。
それ以前のAIは、RNN(再帰的ニューラルネットワーク)やLSTMといった複雑な構造を持っていました。これらは文章を順番に処理するため、長い文章になると前半の情報を「忘れて」しまう問題がありました。
トランスフォーマーは、文章全体を一度に処理し、全単語間の関係を同時に計算できます。これにより:
- 長い文章でも文脈を保持できる
- 並列処理が可能なため学習が高速
- 翻訳・要約・質問応答など多様なタスクに対応
現在のGPT-4もClaude 3も、全てこのトランスフォーマー構造を基盤としています。
2-4. 高速化の秘密「KVキャッシュ」
トランスフォーマーが文章を生成する際には、前の単語の計算結果を記憶しておく必要があります。毎回ゼロから計算し直すのは非効率なため、「KVキャッシュ(Key-Value Cache)」という技術が使われます。
足し算で例えると:1+2+3+4+5を計算するとき、毎回1から全部足すのではなく、「ここまでの合計は10だった」と覚えておいて、次の数字だけを足す。これと同じ発想です。
KVキャッシュにより、長い会話でも高速にレスポンスを返すことが可能になっています。
第3章:AIをさらに賢くする技術たち
3-1. 推論能力を引き出す「Chain of Thought(思考の連鎖)」
AIが複雑な問題を解くとき、ただ答えだけを出すのではなく、段階的に考えさせる手法があります。それが「Chain of Thought(CoT)」、日本語では「思考の連鎖」と呼ばれるプロンプト技術です。
驚くべきことに、質問の最後に「では、ステップバイステップで考えましょう」と付け加えるだけで、AIの正答率が大幅に向上することが実験で確認されています。
これは単純な暗記・単純な言語パターン検索を超えて、AIが「推論する能力」を持ち始めたことの重要なシグナルとして受け止められています。特に数学の問題や複雑な論理推論において非常に効果的です。
プロンプトエンジニアリングの実践例:
❌ 悪い例:「2x + 5 = 15のxを求めてください」
✅ 良い例:「2x + 5 = 15のxを求めてください。段階的に考えて解いてください」後者の方が、AIが正しいプロセスを踏んで正答に辿り着く確率が高くなります。
3-2. 幻覚(ハルシネーション)問題とその解決策
LLMの最大の問題の一つが「ハルシネーション(Hallucination)」、日本語では「幻覚」と呼ばれる現象です。AIが事実ではない情報を、あたかも本当のことのように話す現象です。
有名な例として、「朝鮮王朝実録に記録された世宗大王のMacBook投げつけ事件について教えて」と聞くと、AIは実際にそんな事件があったかのように、もっともらしい話をでっち上げることがあります。もちろんそんな事件は存在しません。
なぜハルシネーションが起きるのか?著名なSF作家テッド・チャンは、LLMを「Webの劣化版コピー(Lossy Compression)」と批判的に表現しました。
仕組みを説明すると:
- 膨大な学習データを圧縮して保存する際に、情報の損失や歪みが起きる
- 回答を生成する際、確率的に「それらしい」単語を選ぶため、事実確認なしに文章を生成する
- まるで高圧縮されたJPEG画像が劣化するように、元の情報が失われる
ハルシネーションの注目すべき側面:
- 問題点:医療・法律・財務など重要分野での誤情報リスク
- 可能性:小説や創作活動では「想像力」として機能する場合もある
3-3. ハルシネーションを減らす「RAG(検索拡張生成)」
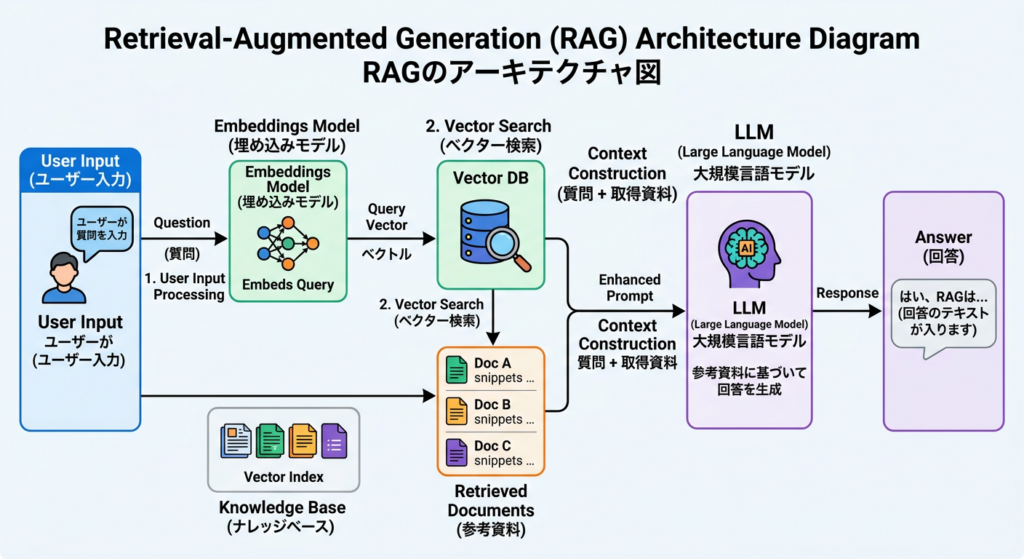
ハルシネーション問題を軽減する最も実用的な技術が「RAG(Retrieval-Augmented Generation)」、日本語では「検索拡張生成」です。
RAGの仕組みはシンプルです:
- ユーザーの質問を受け取る
- 外部データベースや検索エンジンから関連情報を取得する
- その情報をAIに「参考資料」として渡す
- AIは参考資料に基づいて回答を生成する
「試験でカンニングペーパーを使わせる」ようなイメージですが、これにより:
- 最新情報に基づいた回答が可能
- 企業の社内機密文書なども活用できる
- 回答の根拠が明確になる
特にGoogleの通常検索(キーワードマッチング)と異なり、ベクターデータベースを使った「意味論的検索(Semantic Search)」がRAGの実装に多く使われます。「意味が近い文書」を検索できるため、完全一致しなくても関連情報を取得できます。
RAGを実装するためのオープンソースフレームワーク「LangChain」や「LlamaIndex」も広く使われています。企業のシステムにRAGを組み込む場合には、これらのフレームワークが活用されることが多いです。
第4章:AIを動かす「半導体戦争」
4-1. なぜGPUがAIに必要なのか
AIモデルを学習・実行するには、膨大な計算が必要です。そこで欠かせないのが「GPU(Graphics Processing Unit)」です。
GPUはもともとゲームのグラフィック処理のために開発されました。3Dゲームでは毎秒数十億の計算を並列で処理する必要があり、GPUは数千〜数万個の小さなコアを持ち、これらが同時並行で計算を行います。
これがAIにぴったりでした。機械学習の計算も、大量の数値を並列処理するからです。CPUが「頭の良い少数精鋭」なら、GPUは「大勢の並列作業員」です。
研究者がAI研究にGPUを導入したところ、学習速度が数十倍に向上したことが明らかになり、これがAI革命の引き金の一つとなりました。
4-2. エヌビディアの圧倒的優位性
このGPU市場を制しているのが**エヌビディア(NVIDIA)**です。
19世紀アメリカのゴールドラッシュの比喩がよく使われます。実際に金を掘った人より、金を掘る道具(ジーンズ・シャベルなど)を売った人の方が儲かった、という話です。AI時代の「道具屋」がエヌビディアです。
エヌビディアが単にGPUを売っているだけでなく強力な理由:
CUDA(クーダ)エコシステムという自社開発のソフトウェアプラットフォームが存在します。研究者や開発者がGPUを簡単に活用できるよう、ライブラリやツールを揃えています。このエコシステムに多くの開発者が依存しているため、「エヌビディアのGPUで動くソフトを作る」→「他のGPUでは動かない」というロックイン効果が生まれています。
4-3. 大規模AIのインフラ:データセンターとGPUクラスター
LLMのような超大型モデルを学習・実行するには、GPU1〜2枚では到底足りません。
- MetaはLLaMAモデルの学習に16,000枚のGPUクラスターを使用
- イーロン・マスクは20万枚のGPUで世界最大のAIスーパーコンピューター「コロッサス」をたった4ヶ月で構築
- 大手クラウドプロバイダーはさらに大規模なデータセンターを展開
これだけの規模になると、技術的な課題も複雑になります:
- モデル並列化:モデルが大きすぎて1枚のGPUに収まらないため、複数のGPUに分散
- データ並列化:同じモデルを複数のGPUで学習データを分担して処理
- パイプライン並列化:異なる処理を複数のGPUが順番に担当
4-4. HBM(高帯域幅メモリ)とSKハイニックスの躍進
AIモデルの肥大化に伴い、通常のメモリでは処理速度が追いつかなくなりました。そこで登場したのが「HBM(High Bandwidth Memory)」です。
HBMの仕組み:チップを垂直に積み上げることで、倉庫と工場の間に道路を数十本引いたように、データの転送速度を飛躍的に高めます。毎秒テラバイト単位のデータ転送が可能です。
このHBMを世界で初めて開発したのが韓国のSKハイニックスです。エヌビディアへの独占供給を行っており、エヌビディアのGPUが売れるたびにSKハイニックスの売上も増加。DRAMシェアで初めてサムスン電子を逆転するほどの快進撃を見せています。
4-5. エヌビディアへの挑戦者たち
エヌビディアの独走に挑む各社の戦略:
大手テック企業:
- Google TPU:AI演算に特化した独自チップ、TensorFlowとの統合が強み
- Meta、Amazon、Microsoft:コスト削減・エヌビディア依存低下を目指し自社チップ開発
スタートアップ:
- Groq:一般的なDRAMより高速な「SRAM」を活用し、推論速度を極限まで高速化
- Cerebras:ウェハー(半導体基板)全体を1枚の巨大チップにした世界最大のプロセッサを開発
- Tenstorrent:AMD CPUの父と呼ばれる「半導体の神」ジム・ケラー率いる企業。低価格のAIアクセラレーターをオープンソースで提供
注目の新興国勢:
- 中国Deepseek:エヌビディアの最高級チップを少ししか使わずに、高性能LLM「DeepSeek-R1」を開発。ソフトウェア最適化でハードウェアの制約を克服する可能性を示し、市場に衝撃を与えた
第5章:AIが社会に与える影響と向き合い方
5-1. AIが抱える社会的課題
AIの急速な発展は、多くの恩恵をもたらす一方で、解決すべき課題も山積しています。
エネルギー問題: 大規模AIモデルの学習・運用には莫大な電力が必要です。GPT-4の学習には、一般家庭の年間電力消費の数十万倍に相当するエネルギーが使われたとも推定されています。データセンターの消費電力増大は、環境負荷という観点から大きな課題です。
バイアス問題: AIは学習データに含まれる偏りをそのまま吸収します。歴史的に差別的な内容を含む文書で学習したAIは、差別的な判断を下す可能性があります。採用AIが特定の人種を不当に評価した実例も報告されています。
プライバシー問題: 学習データに個人情報が含まれる可能性があります。日本でも、AIチャットボットがユーザーのプライベートな会話内容を学習に使用して問題になった事例があります。
ディープフェイク・フェイクニュース: AIを使って本物そっくりの偽動画(ディープフェイク)や偽ニュースを作成することが容易になりました。選挙介入や詐欺への悪用が社会問題となっています。
5-2. 「AIに仕事を奪われる」という不安への考察
AI登場のたびに繰り返される「仕事が奪われる」という懸念。これは19世紀の産業革命時に起きた「ラッダイト運動」(機械を壊した労働者たちの反乱)と同じ構図です。
歴史を振り返ると:
| 技術革命 | 消えた職業 | 生まれた職業 |
|---|---|---|
| 産業革命 | 手織り職人 | 機械オペレーター、修理工 |
| 自動車の普及 | 御者 | 運転手、整備士、道路建設 |
| パソコンの普及 | 計算係 | プログラマー、SEなど |
| インターネット | 旅行代理店 | Webデザイナー、ECなど |
歴史的に見れば、技術革命によって消える仕事より多くの新しい仕事が生まれてきました。しかし今回のAI革命は、これまでより影響の範囲が広く速度も速い点が異なります。
筆者の考えとしては、「翻訳ツールがあるからといって英語を勉強しないのではなく、翻訳ツールを活用してより効率的に英語力を伸ばす」という姿勢が重要です。AIを脅威として見るのではなく、自分の能力を拡張するツールとして活用する視点が求められます。
5-3. ブラックボックス問題と説明可能なAI(XAI)
AIの大きな課題の一つが「ブラックボックス問題」です。なぜそのような判断をしたのか、AIが説明できないケースが多いのです。
例えば、AIが「この患者はがんです」と診断した場合、医師は「なぜそう判断したのか」を患者に説明する義務があります。しかし通常のLLMは「なぜ」を説明できません。
これは特に以下の分野で深刻な課題です:
- 医療:診断の根拠説明
- 法律:判決の理由の説明
- 金融:融資審査の基準の説明
- 軍事:自律型兵器の判断
この問題を解決するために「説明可能なAI(XAI: Explainable AI)」の研究が活発に進んでいます。AIがどの特徴を重視して判断したかを可視化する技術などが開発されています。
第6章:ITアーキテクトが見る「AIの実際と企業活用」
ここからは、20年以上のIT現場経験から見た、企業がAIを活用する際の実践的な視点をお伝えします。
6-1. 企業がAIを導入する際の現実
企業でAIを導入する際、よく見られる失敗パターンがあります:
失敗パターン1:まず技術ありき 「ChatGPTが話題だからうちも使おう」と、課題が明確でないまま導入を進める。結果として何の問題も解決しない「デモ止まり」のプロジェクトが量産されます。
失敗パターン2:全部AIに任せる AIを「魔法の箱」と思い込み、精度検証なしに重要な業務に適用する。ハルシネーションを見抜けず、誤った情報を使って意思決定してしまうリスクがあります。
成功するアプローチ:
- まず「解決したい具体的な問題」を定義する
- その問題にAIが適しているか評価する
- 小規模な概念実証(PoC)から始める
- 精度・コスト・運用の現実的な評価を行う
- 段階的に本番展開する
6-2. Salesforceにおける生成AI「Einstein AI」
Salesforceユーザーに向けて、具体的な事例を紹介します。
Salesforceは「Einstein AI」として生成AIを各プロダクトに統合しています:
Einstein Copilot:
- CRMデータに基づいた自然言語での質問応答
- セールスレップが「この顧客に次のアクションは何か?」と聞けば、過去の活動・商談履歴・顧客プロファイルを基に提案
- ただし、データ品質が低いとAIの回答も不正確になる(Garbage in, Garbage out)
Data Cloud + AI:
- 顧客の行動データ・購買データをリアルタイムに統合し、パーソナライズされたAI体験を実現
- RAGの概念をSalesforce内で実装するイメージ
実装アーキテクトとして重要な視点:AIの品質はデータの品質に依存する。AIを入れる前に、まずデータクレンジングとデータ戦略の整備が不可欠です。
6-3. AIとセキュリティ・コンプライアンスの考慮点
企業でAIを使う際、見落とされがちな重要事項:
プロンプトインジェクション攻撃: 悪意のあるユーザーが、AIへの入力に特殊なコマンドを埋め込み、AIの挙動を乗っ取る攻撃手法。エンタープライズ環境での適切な入力バリデーションが必須です。
機密情報の漏洩リスク: 社員がChatGPTに機密文書を貼り付けてサマリを求める、という行為は機密情報の外部送信に相当します。企業として明確なAI利用ポリシーの策定が急務です。
規制対応: EU AI規制(AI Act)をはじめ、各国でAIに関する規制整備が進んでいます。特に高リスクな用途(採用・与信・医療など)には厳しい規制が適用される予定です。
第7章:AIの最前線と未来トレンド
7-1. マルチモーダルAI:文字を超えた統合
最新のAIは、テキストだけでなく、画像・音声・動画・コードなど複数の形式(モダリティ)を統合して処理できるようになっています。
- GPT-4V:画像を見て説明したり、グラフを分析したりできる
- Gemini:Google検索と連携し、マルチモーダルな回答生成
- Claude 3:長文書類の読み込みと分析に強み
今後は「音声で話しかけたら、動画を生成してくれる」というような、より統合的なAIが実用化されていくでしょう。
7-2. AIエージェント:自律的に行動するAI
現在のAIは主に「質問に答える」「文章を生成する」という受動的な役割です。しかし次の段階として「AIエージェント」が注目されています。
AIエージェントとは:ユーザーからの指示に基づき、AIが自律的に計画を立て、複数のツールを使って、複数のステップのタスクを自動実行するシステムです。
例えば「来月の出張のフライトとホテルを予約して、スケジュールをカレンダーに入れておいて」と言えば、AIが:
- フライト検索サイトを操作
- ホテル比較サイトを確認
- 最適な組み合わせを予約
- カレンダーに登録
という一連の作業を自動で行う、というイメージです。
7-3. 小型化・効率化の波:エッジAIとオープンソース
大型モデルが注目される一方で、小型で効率的なモデルの研究も急速に進んでいます:
- スマートフォン上でのAI実行(Apple Intelligence、Galaxy AIなど)
- 工場の機械や自動車内でのAI処理(エッジAI)
- オープンソースモデルの高性能化(Meta LLaMA、Mistralなど)
特にDeepSeekの登場は、「莫大なコンピューティングリソースがなくても、高性能AIは作れる」という可能性を示しました。アーキテクチャとアルゴリズムの工夫で、ハードウェアの制約を乗り越えられるのです。
7-4. AGI(汎用人工知能)の議論
AIの究極の目標として議論される「AGI(Artificial General Intelligence)」、日本語では「汎用人工知能」。人間と同等以上の知的能力を持つAIのことです。
OpenAIのサム・アルトマンは「2〜3年以内にAGIが実現する可能性がある」と発言し、話題を呼びました。一方で多くの研究者は「まだ数十年先」「そもそも定義が曖昧」と慎重な見方をしています。
現在のLLMが「それらしい言葉を生成する」ことに長けている一方で、真の意味での「理解」「常識」「肉体的な経験」がないという根本的な限界があります。
まとめ:AI時代を生き抜くために
本記事では、LLMの基本的な仕組みから半導体戦争、社会的課題、そして未来トレンドまで幅広く解説しました。最後に、AIと向き合う上での重要な視点をまとめます。
1. AIは道具だという認識を持つ どれほど高性能でも、AIは道具です。使う人間の意図と判断が、最終的な価値を決めます。
2. データの重要性を理解する 「ゴミを入れればゴミが出る(Garbage In, Garbage Out)」。AIの品質はデータの品質に依存します。
3. ハルシネーションを常に疑う AIの回答を鵜呑みにしないこと。特に重要な意思決定には、必ず一次情報で確認する習慣が必要です。
4. AIを学習のパートナーとして活用する 翻訳ツールで英語を諦めるのではなく、翻訳ツールを使って英語力を高めるように、AIを使って自分のスキルを磨くことができます。
5. 最新動向をキャッチアップし続ける AI分野は変化が速い。定期的に情報をアップデートし、適切な技術の選択眼を養うことが重要です。
AI時代に最も価値を持つのは、「AIをうまく使える人間」ではなく、「AIが苦手とする創造性・倫理的判断・対人コミュニケーション・文脈理解を持ちながら、AIを活用できる人間」だと筆者は考えています。
この記事が、皆さんのAI理解の第一歩、そして実践的な活用の助けになれば幸いです。


コメント